
トールキンの「指輪物語」に登場する力の 1 つの指輪のように、デオキシリボ核酸 (DNA)はあらゆる細胞のマスター分子です。それには、後続の世代に受け継がれる重要な情報が含まれています。それ自体および他の分子(タンパク質)の生成を調整します。少しでも変更すると、重大な結果が生じる可能性があります。修復不可能なほど破壊されると、細胞は死滅します。
多細胞生物の細胞の DNA が変化すると、種の特性に変化が生じます。長期間にわたって、自然選択がこれらの変動に作用して、種を進化または変化させます。
犯罪現場での DNA 証拠の有無は、有罪判決と無罪判決の違いを意味する可能性があります。 DNA は非常に重要であるため、米国政府は多くの遺伝病を理解し、治療法を発見することを期待して、ヒトゲノム内のDNA の配列を決定するために巨額の資金を費やしました。最後に、1 つの細胞の DNA から、動物、植物、さらには人間のクローンを作成することもできます。
しかし、 DNAとは何でしょうか?どこで見つかりますか?何がそんなに特別なのでしょうか?どのように機能するのでしょうか?この記事では、DNA の構造を深く考察し、DNA がどのように作られるのか、そして DNA が人のすべての特性をどのように決定するのかを説明します。まず、DNAがどのように発見されたかを見てみましょう。
DNA は、核酸と呼ばれる分子の一種です。核酸はもともと 1868 年にスイスの生物学者 によって発見され、包帯上の膿細胞から DNA を単離しました。ミーッシャーは核酸に遺伝情報が含まれているのではないかと疑っていましたが、それを確認することはできませんでした。
1943年、ロックフェラー大学のオズワルド・エイブリーらは、肺炎球菌という細菌から採取したDNAが非感染性細菌を感染させる可能性があることを示した。これらの結果は、DNA が細胞内の情報を含む分子であることを示しました。 DNA の情報の役割は 1952 年にアルフレッド ハーシーとマーサ チェイスが新しいウイルスを作るために、バクテリオファージウイルスがタンパク質ではなく DNA を宿主細胞に注入することを実証したことでさらに裏付けられました。
そのため、科学者たちは長い間、DNA の情報としての役割について理論化していましたが、この情報がどのようにエンコードされ、伝達されるのかは誰も知りませんでした。多くの科学者は、分子の構造がこのプロセスにとって重要であると推測しました。 1953 年、ジェームズ D. ワトソンとフランシス クリックはケンブリッジ大学で DNA の構造を発見しました。
基本的に、ワトソンとクリックは、分子モデリング技術と他の研究者 (モーリス・ウィルキンス、ロザリンド・フランクリン、アーウィン・シャルガフ、ライナス・ポーリングなど) からのデータを使用して、DNA の構造を解明しました。ワトソン、クリック、ウィルキンスはこの発見に対して賞を受賞した(フランクリンはウィルキンスの協力者であり、ワトソンとクリックに構造を明らかにする重要なデータを提供したが、賞が授与される前に亡くなった)。
DNA構造
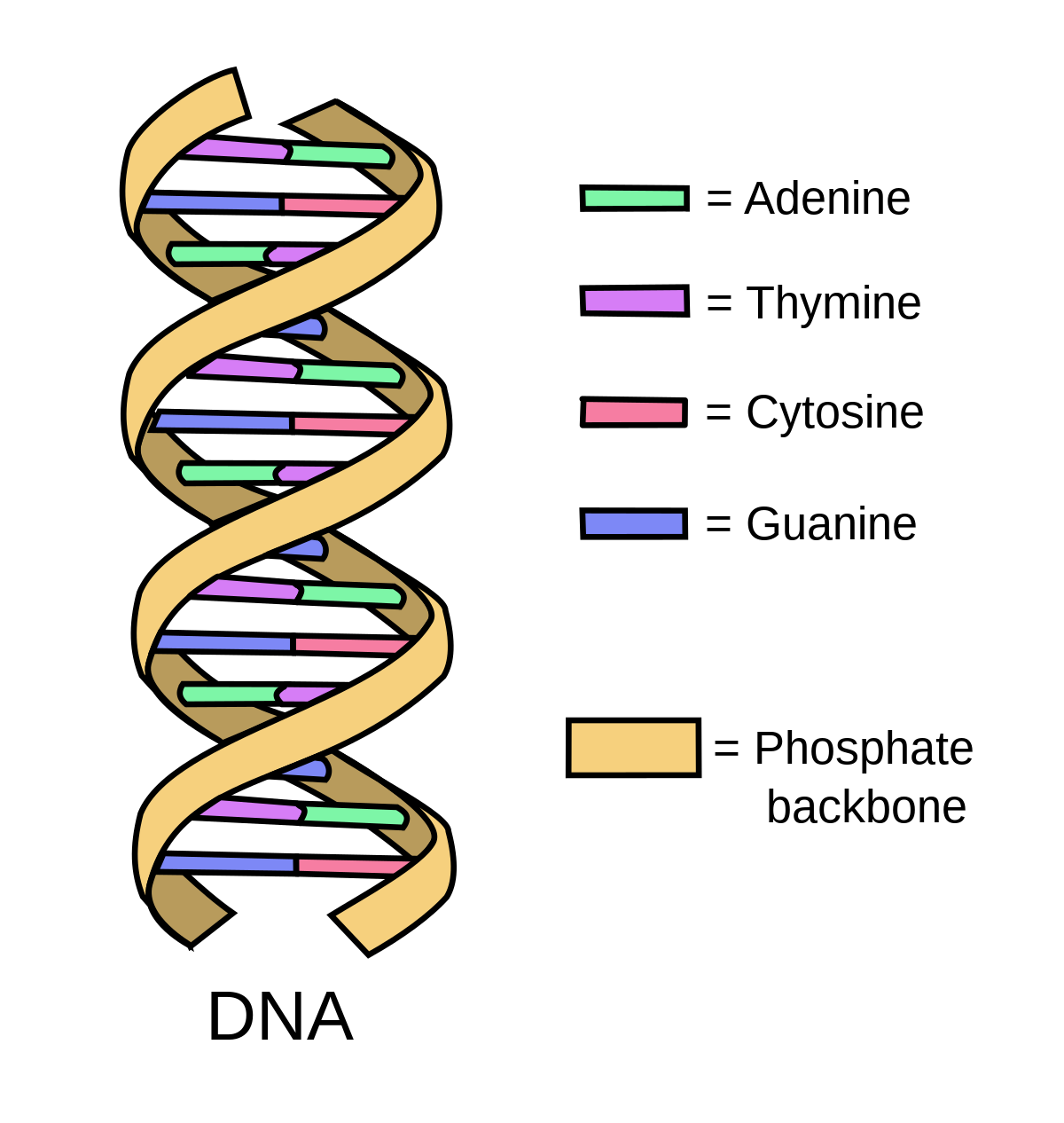
DNA は、細胞内の情報を含む分子である核酸の 1 つです (リボ核酸、または RNA はもう 1 つの核酸です)。 DNA は人間のあらゆる細胞の核に存在します。 DNA の情報:
- 細胞が(RNAとともに)私たちのすべての生物学的特性を決定する新しいタンパク質を生成するように導きます
- ある世代から次の世代に渡される(コピーされる)
Watson と Crick が説明しているように、これらすべての機能の鍵は にあります。
複雑に見えるかもしれませんが、細胞内の DNA は、ヌクレオチドと呼ばれる 4 つの異なる部分からなるパターンにすぎません。 4 つの形状のみを含むブロックのセット、または 4 つの文字のみを含むアルファベットを想像してください。 DNA はこれらのブロックまたは文字の長い文字列です。各ヌクレオチドは、一方の側でリン酸基に結合し、もう一方の側で窒素含有塩基に結合した糖 (デオキシリボース) から構成されます。
窒素塩基には、プリン(二重環構造) とピリミジン(単環構造) と呼ばれる 2 つのクラスがあります。 DNA のアルファベットの 4 つの塩基は次のとおりです。
- アデニン (A) : プリンの一種
- シトシン(C) : ピリミジン
- グアニン (G) : プリンの一種
- チミン (T) : ピリミジン
ワトソンとクリックは、DNA には 2 つの側面または鎖があり、これらの鎖がねじれたはしごのようにねじれていること、つまり二重らせんであることを発見しました。ラダーの側面は、互いに結合した隣接するヌクレオチドの糖リン酸部分を構成します。
1 つのヌクレオチドのリン酸は、次のヌクレオチドの糖と共有結合(1 対以上の電子が 2 つの原子によって共有される結合) します。リン酸間の水素結合により、DNA 鎖がねじれます。窒素含有塩基ははしごの内側を向いており、横木のように反対側の塩基と対を形成します。各塩基対は、水素結合によって結合した 2 つの相補的ヌクレオチド (プリンとピリミジン) から形成されます。 DNA の塩基対は、アデニンとチミン、およびシトシンとグアニンです。
水素結合は、水素原子と、酸素、窒素、フッ素などのより電気陰性度の高い原子との間に生じる弱い化学結合です。関与する原子は、同じ分子上 (隣接するヌクレオチド) に位置することも、異なる分子上 (異なる DNA 鎖上の隣接するヌクレオチド) に位置することもあります。水素結合には、共有結合やイオン結合のような電子の交換や共有は含まれません。弱い引力は磁石の両極間の引力に似ています。水素結合は短距離で発生し、簡単に形成および切断されます。分子を安定化することもできます。
セル内へのフィッティング
DNAは長い分子です。たとえば、大腸菌などの典型的な細菌は、約 3,000 個の遺伝子を含む 1 つの DNA 分子を持っています。この DNA 分子を引き伸ばすと、長さは約 1 ミリメートルになります。ただし、典型的な大腸菌の長さはわずか 3 ミクロン (1 ミリメートルの 1,000 分の 3) です。そのため、細胞内に収まるように、DNA は高度にコイル状に巻かれ、ねじれて 1 つの環状染色体になります。
植物や動物のような複雑な生物は、多くの異なる染色体上に 50,000 ~ 100,000 の遺伝子を持っています (ほとんどの人間は46 本の染色体を持っています)。これらの生物の細胞内では、DNA はヒストンと呼ばれるビーズ状のタンパク質の周りにねじれています。また、ヒストンはしっかりとコイル状になって染色体を形成し、細胞の核内にあります。
細胞が複製すると、染色体 (DNA) がコピーされ、各子孫細胞または娘細胞に分配されます。非性細胞はコピーされる各染色体の 2 つのコピーを持ち、各娘細胞は 2 つのコピーを受け取ります (有糸分裂)。減数分裂中、前駆細胞は各染色体のコピーを 2 つ持ち、コピーされて 4 つの性細胞に均等に分配されます。性細胞(精子と卵子)は、各染色体のコピーを 1 つだけ持っています。精子と卵子が受精で結合すると、子孫は各染色体のコピーを 2 つずつ持ちます。
DNA複製
DNA には、細胞のすべてのタンパク質を作るための情報が含まれています。これらのタンパク質は生体のすべての機能を実行し、生体の特性を決定します。細胞が再生するとき、この情報をすべて娘細胞に渡さなければなりません。
細胞が複製する前に、まず DNA を複製、つまりコピーを作成する必要があります。 DNA複製がどこで起こるかは、細胞が原核生物であるか真核生物であるかによって異なります。 DNA複製は、原核生物の細胞質および真核生物の核で起こります。 DNA 複製がどこで起こるかに関係なく、基本的なプロセスは同じです。
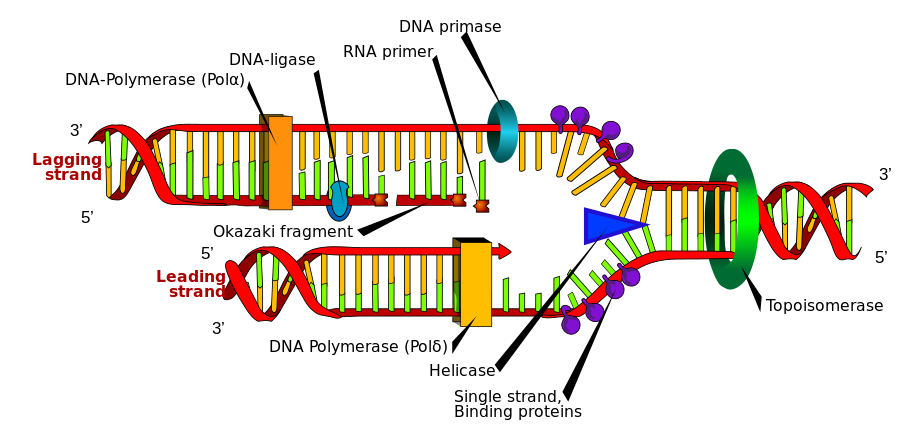
DNA の構造は、DNA 複製を容易にします。二重らせんの各辺は反対(逆平行)方向に走っています。この構造の利点は、中央で解凍でき、それぞれの側がもう一方の側のパターンまたはテンプレートとして機能できることです ( 「半保存的複製」と呼ばれます)。ただし、DNA は完全には解凍されません。複製フォークと呼ばれる小さな領域で解凍され、分子の全長に沿って移動します。
詳細を見てみましょう:
- DNA ジャイレースと呼ばれる酵素が二重らせんに切れ目を入れ、それぞれの側を分離します。
- ヘリカーゼと呼ばれる酵素が二本鎖 DNA をほどきます。
- 一本鎖結合タンパク質(SSB) と呼ばれるいくつかの小さなタンパク質が一時的に各側に結合し、それらを分離した状態に保ちます。
- DNA ポリメラーゼと呼ばれる酵素複合体は、DNA 鎖を「歩き」、各鎖に新しいヌクレオチドを追加します。ヌクレオチドは、既存のスタンド上の相補的ヌクレオチドと対を形成します (A と T、G と C)。
- DNA ポリメラーゼのサブユニットが新しい DNA を校正します。
- DNA リガーゼと呼ばれる酵素は、断片を 1 つの長く連続した鎖に封じ込めます。
- 新しいコピーは自動的に再び巻き取られます。
細胞の種類が異なれば、DNA の複製速度も異なります。髪や爪、骨髄細胞など、細胞の中には常に分裂するものもあります。他の細胞は数回の細胞分裂を経て停止します (脳、筋肉、心臓などの特殊な細胞も含まれます)。最後に、一部の細胞は分裂を停止しますが、損傷を修復するために分裂を誘導することができます (皮膚細胞や肝細胞など)。絶えず分裂しない細胞では、DNA 複製/細胞分裂の合図は化学物質の形で届きます。これらの化学物質は、体の他の部分 (ホルモン) または環境に由来する場合があります。
ただし、一部のウイルスは DNA の代わりに RNA を情報伝達手段として使用します。ほとんどの動物は各染色体のコピーを 2 つ持っています。対照的に、植物は複数の染色体のコピーを 2 つ以上持つことがありますが、これは通常、細胞の複製中の染色体の分布エラーによって生じます。動物では、この種のエラーは通常、致命的な場合が多い遺伝性疾患を引き起こします。いくつかの理由は不明ですが、この種のエラーは植物にとってそれほど致命的ではありません。
DNAの働き
DNA には身体的特徴に関するすべての情報が含まれており、これらの情報は基本的にタンパク質によって決定されます。 DNAにはタンパク質を作るための指示が含まれています。 DNA では、各タンパク質は遺伝子(単一のタンパク質がどのように作られるかを指定する DNA ヌクレオチドの特定の配列) によってコードされています。具体的には、遺伝子内のヌクレオチドの順序は、タンパク質を作るために結合する必要があるアミノ酸の順序と種類を指定します。
タンパク質は、アミノ酸と呼ばれる化学物質の長い鎖で構成されています。さまざまな機能を持つさまざまな種類のタンパク質があります。
- 酵素は化学反応を実行します(消化酵素など)。
- 構造タンパク質は建築材料(コラーゲンや爪のケラチンなど)です。
- 物質(血液中の酸素を運ぶヘモグロビンなど)を運ぶタンパク質を輸送します。
- 収縮タンパク質(アクチンやミオシンなど) は筋肉を圧縮させます。
- 卵白のアルブミンや脾臓の鉄貯蔵フェリチンなど、物質を保持する貯蔵タンパク質。
- ホルモン(インスリン、エストロゲン、テストステロン、コルチゾールなど)は、体内の細胞間に信号を送ります。
鎖内のアミノ酸の特定の配列が、あるタンパク質を他のタンパク質と区別するものです。この配列は DNA にコードされており、1 つの遺伝子が 1 つのタンパク質をコードしています。
DNA はどのようにしてタンパク質の情報をエンコードするのでしょうか? DNAの塩基は4つしかありませんが、タンパク質に使用できるアミノ酸は20個あります。したがって、3 つのヌクレオチドのグループは、20 アミノ酸のうちどのアミノ酸がタンパク質に入るかを指定するコドンを形成します。 3 塩基のコドンから 64 の可能なパターン (4*4*4) が得られ、これは 20 個のアミノ酸を指定するには十分以上です。
可能なコドンは 64 個あり、アミノ酸は 20 個しかないため、遺伝暗号にはある程度の繰り返しがあります。また、遺伝子内のコドンの順序は、タンパク質内のアミノ酸の順序を指定します。特定のタンパク質を指定するには、100 ~ 1,000 コドン (300 ~ 2,000 ヌクレオチド) が必要になる場合があります。各遺伝子には、遺伝子の始まり (開始コドン) と終わり (停止コドン) を指定するコドンもあります。
タンパク質の構築: 転写
家を建てるのとよく似ています。
- マスターの設計図は DNA であり、新しいタンパク質 (ハウス) を構築するためのすべての情報が含まれています。
- マスター設計図の作業用コピーはメッセンジャー RNA (mRNA) と呼ばれ、DNA からコピーされます。
- 構築部位は、原核生物の細胞質または 真核生物の小胞体(ER) です。
- 建築材料はアミノ酸です。
- 建設作業員はリボソームであり、RNA 分子を転送します。
新築建設の各段階を詳しく見てみましょう。
真核生物では、DNA が核から離れることはないため、その情報はコピーされなければなりません。このコピープロセスは転写と呼ばれ、そのコピーがmRNAです。転写は細胞質 (原核生物) または核 (真核生物) で行われます。転写はRNAポリメラーゼと呼ばれる酵素によって行われます。
mRNA、RNAポリメラーゼを作成するには:
- プロモーターと呼ばれる遺伝子の特定の配列で DNA 鎖に結合します。
- 2 本の DNA 鎖を解きほぐします。
- DNA 鎖の 1 つをガイドまたはテンプレートとして使用します
- 新しいヌクレオチドを DNA 鎖上の補体と照合します (G と C、A と U — RNA にはチミン (T) の代わりにウラシル (U) があることに注意してください)
- これらの新しい RNA ヌクレオチドを結合して DNA 鎖 (mRNA) のコピーを形成します。
- 塩基の終結配列 (停止コドン) に遭遇すると停止します。
mRNA は、(相補的な二本鎖らせんを形成したいという DNA の欲求とは対照的に) 一本鎖状態で生存することに満足しています。原核生物では、mRNA 内のすべてのヌクレオチドが新しいタンパク質のコドンの一部です。ただし、真核生物に限っては、タンパク質をコードしないイントロンと呼ばれる余分な配列が DNA と mRNA に存在します。
この mRNA はさらに処理されます。
- イントロンが切り取られてしまいます。
- コード配列は一緒にスプライスされます。
- 特殊なヌクレオチドの「キャップ」が一方の端に追加されます。
- もう一方の端には、100 ~ 200 個のアデニン ヌクレオチドからなるロング テールが付加されます。
なぜこの処理が真核生物で起こるのかは誰も知りません。最後に、特定のタンパク質に対する細胞のニーズに応じて、いつでも多くの遺伝子が同時に転写されています。
設計図の作業用コピー (mRNA) は、作業員が新しいタンパク質を構築する建設現場に運ばれなければなりません。細胞が大腸菌などの原核生物の場合、その部位は細胞質です。細胞がヒト細胞などの真核生物である場合、mRNA は核膜の大きな穴 (核孔) を通って核を出て、小胞体 (ER) に進みます。
次に、翻訳、つまり組み立てプロセスについて学びます。
タンパク質の構築: 翻訳
家のたとえ話を続けると、設計図の作業用コピーが現場に到着したら、作業員は指示に従って材料を組み立てなければなりません。このプロセスは翻訳と呼ばれます。タンパク質の場合、働くのはリボソームとトランスファー RNA (tRNA)と呼ばれる特別な RNA 分子です。構成材料はアミノ酸です。
まず、リボソームについて見てみましょう。リボソームはリボソーム RNA (rRNA) と呼ばれる RNA で構成されています。原核生物では、rRNA は細胞質で作られます。真核生物では、rRNA は核小体で作られます。リボソームには 2 つの部分があり、mRNA のどちらかの側に結合します。大きな部分の中には、mRNA の 2 つの隣接するコドン、2 つの tRNA 分子、および 2 つのアミノ酸が収まる 2 つの「部屋」(P サイトと A サイト) があります。まず、P サイトは mRNA の最初のコドンを保持し、A サイトは次のコドンを保持します。
次に、tRNA 分子を見てみましょう。各 tRNA にはアミノ酸の結合部位があります。各 tRNA は単一のアミノ酸に特異的であるため、その特定のアミノ酸をコードする mRNA 上のコドンを認識できなければなりません。したがって、各 tRNA は、錠と鍵のように、適切な mRNA コドンと一致するアンチコドンと呼ばれる特定の 3 ヌクレオチド配列を持っています。
たとえば、mRNA 上のコドンにアミノ酸フェニルアラニンをコードする配列… ウラシル-ウラシル-ウラシル … (UUU)がある場合、フェニルアラニン tRNA のアンチコドンはアデニン-アデニン-アデニンになります。 (AAA) ; RNA では A が U と結合することを思い出してください。 tRNA 分子は細胞質内に浮遊し、遊離アミノ酸に結合します。アミノ酸に結合すると、tRNA (アミノアシル tRNA とも呼ばれます) はリボソームを探します。
最後に、新しいタンパク質の合成における出来事を見てみましょう。たとえば、次の配列を持つ小さな mRNA 分子を考えてみましょう。
- すべての mRNA 分子は開始コドン AUGで始まります。 UGA、UAA、UAG は終止コドンです。終止コドンには対応する tRNA 分子がありません。 (実際の mRNA 分子には数百のコドンがあります。)
- tRNA アンチコドンの対応する配列はUACになります。
- 終止コドンに対応する tRNA はありません。
- この小さなmRNAによって特定されるアミノ酸配列はメチオニンです。
私たちは、遺伝暗号の表を使用することで、このアミノ酸の配列を知ることができます。上記の遺伝コード表は mRNA 用であり、コドンの 1 番目、2 番目、および 3 番目の位置の塩基と、対応するアミノ酸を指定します。
ページ上部の表を使用して、mRNA コドン AUG で指定されるアミノ酸を読み取ってみましょう。まず、表の最初の列の最初の位置のコドン (A) に左手の指を置きます。左指を最初の行の 2 番目の位置のコドン (U) の下の行に移動します。次に、最後の列 (G) の同じ行にある 3 番目の位置のコドン (G) に右手の指を置きます。右手の指を左の指と接するまで行上で移動し、アミノ酸を読み取ります。メチオニンが表示されるはずです。
タンパク質合成プロセス
ここで、サンプル mRNA からタンパク質が合成される順序を見てみましょう。
- リボソームは、P サイトの AUG コドンと A サイトの UUU コドンで mRNA に結合します。
- メチオニンが結合したアミノアシル tRNA (アンチコドン = UAC) がリボソームの P サイトに入ります。
- フェニルアラニンが結合したアミノアシル tRNA (アンチコドン = AAA) がリボソームの A 部位に入ります。
- メチオニンとフェニルアラニンの間に化学結合が形成されます (タンパク質では、この共有結合はペプチド結合と呼ばれます)。
- メチオニン特異的 tRNA は P サイトを離れ、別のメチオニンを集めに行きます。
- リボソームはシフトし、P サイトにはフェニル アラニン tRNA が結合した UUU コドンが含まれ、次のコドン (ACA) が A サイトを占めるようになります。
- スレオニンが結合したアミノアシル tRNA (アンチコドン) がリボソームの A 部位に入ります。
- フェニルアラニンとスレオニンの間にペプチド結合が形成されます。
- フェニルアラニン特異的 tRNA は P サイトを離れ、別のフェニルアラニンを探しに出かけます。
- リボソームはコドンを 1 つ下にシフトして、停止配列が A サイトに配置されるようにします。停止配列に遭遇すると、リボソームは mRNA から切り離され、2 つの部分に分割されます。スレオニン特異的 tRNA がスレオニンを放出して離れ、新しいタンパク質が浮遊します。
いくつかのリボソームが mRNA 分子に次々と結合し、タンパク質を作り始めます。したがって、1 つの mRNA から複数のタンパク質を作ることができます。実際、大腸菌では、転写が終了する前に mRNA の翻訳が始まります。
ミトコンドリアは細菌の初期の形態に似ており、地球上の生命の歴史の初期に真核細胞に取り込まれたと考えられています。細菌は細胞と共存(細胞内共生)し、ミトコンドリアに進化しました。ミトコンドリア DNA のもう 1 つのユニークな点は、母親 (卵細胞内に存在するミトコンドリア) からのみ受け継がれることです。卵子を受精させる精細胞には父親からのミトコンドリアが含まれていますが、放出されて受け継がれることはありません。
DNA の突然変異、変異、および配列決定
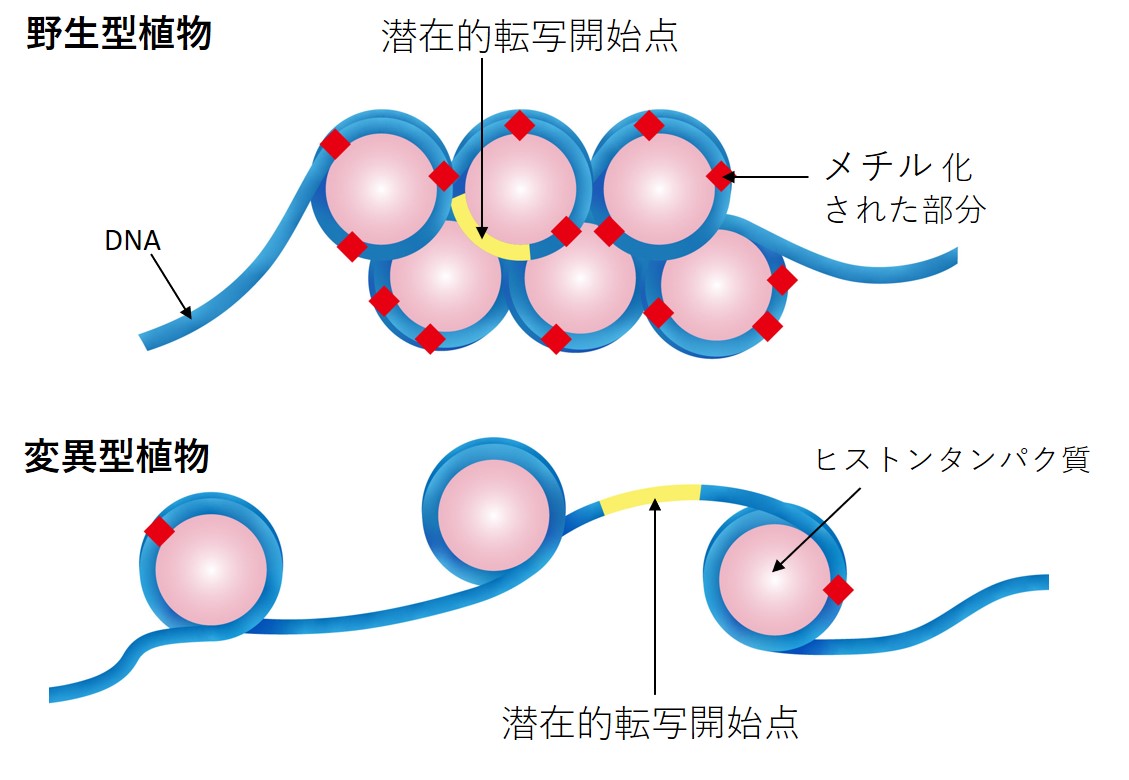
ヒトゲノムには 50,000 ~ 100,000 個の遺伝子があります。 DNA ポリメラーゼが DNA 配列をコピーする際、いくつかの間違いが発生します。たとえば、遺伝子内の 1 つの DNA 塩基が別の DNA 塩基に置換される可能性があります。これは、遺伝子の突然変異(特に点突然変異) または変異と呼ばれます。遺伝暗号には冗長性が組み込まれているため、この間違いは遺伝子によって作られるタンパク質には大きな影響を与えない可能性があります。
場合によっては、エラーがコドンの 3 番目の塩基にあり、依然としてタンパク質内の同じアミノ酸を指定している可能性があります。他の場合には、それはコドン内の他の場所にあり、異なるアミノ酸を指定する可能性があります。変更されたアミノ酸がタンパク質の重要な部分にない場合、悪影響は生じない可能性があります。ただし、変化したアミノ酸がタンパク質の重要な部分にある場合、タンパク質に欠陥があり、正常に機能しないか、まったく機能しない可能性があります。この種の変化は病気を引き起こす可能性があります。
DNA の他の種類の突然変異は、DNA の小さなセグメントが染色体から切り離されるときに発生する可能性があります。これらのセグメントは染色体の別の場所に戻され、通常の情報の流れを中断する可能性があります。これらのタイプの突然変異 (欠失、挿入、逆位) は通常、重大な結果をもたらします。
ヒトゲノムには、タンパク質をコードしていない余分な DNA がたくさんあります。科学者たちはかつて、非コード DNA には本当の目的はないと信じていました。しかし、それらの遺伝子の少なくとも一部は、遺伝子がいつどこでオンまたはオフになるかを決定したり、タンパク質の組み立てを支援したりするなど、細胞の機能に不可欠であることがわかっています。これらは必ずしも善良な義務ではありません。たとえば、重要なタンパク質のパターンを変える非コード DNA の小さな変化は、正常な発育を妨害し、健康上の問題を引き起こす可能性があります。
ヒトゲノム プロジェクト(HGP) は、ヒトゲノム全体の配列を決定し、「どのような遺伝子が存在するのか?」といういくつかの基本的な質問に答えることを目的として 1990 年代に開始されました。それらはどこにありましたか?遺伝子とそこに介在する DNA (非コード DNA) の配列は何でしょうか?は、2000 年に最初のヒトゲノム配列の草案を提供し、2003 年に最終的な高品質バージョンを提供しました。それ以来、数年間に、識別から診断に至るあらゆる分野で医学の進歩への道が開かれてきました。
この任務は、人類初の月面着陸というアポロ宇宙計画の命令に沿った記念碑的なものでした。 HGP の科学者と請負業者は、自動化され低コストで DNA を配列する新しい技術を開発しました。
基本的に、DNA の配列を決定するには、DNA のコピーに必要なすべての酵素とヌクレオチド (A、G、C、T) を試験管に入れます。ヌクレオチドのごく一部には蛍光色素が付いています (タイプごとに異なる色)。次に、配列を決定したい DNA を試験管に入れてインキュベートします。
インキュベーションプロセス中に、サンプル DNA は何度もコピーされます。どのコピーでも、蛍光ヌクレオチドが挿入されるとコピープロセスが停止します。したがって、インキュベーションプロセスの最後には、蛍光ヌクレオチドの 1 つで終わるさまざまなサイズの元の DNA の断片が多数得られます。
ヒトゲノムの要素がどのように機能し、環境と相互作用するかを理解しようとするにつれて、DNA テクノロジーは発展し続けるでしょう。